
W dzisiejszym artykule dowiesz się o czterech problemach, z którymi możesz się zetknąć w trakcie pracy z sieciami. Skutki niektórych z nich są mało widoczne, podczas gdy inne powodują naprawdę spore utrudnienia w prawidłowej pracy sieci. O czym tu mowa? O routingu asymetrycznym, zjawisku unicast floodingu, pakietach docierających do hosta docelowego w niewłaściwej kolejności oraz o tzw. micro-bursts. Przyjrzyjmy się nieco bliżej każdemu z tych problemów.
Routing asymetryczny
Routing asymetryczny to sytuacja, w której ruch wychodzący z sieci wraca do niej inną ścieżką niż ta początkowa:
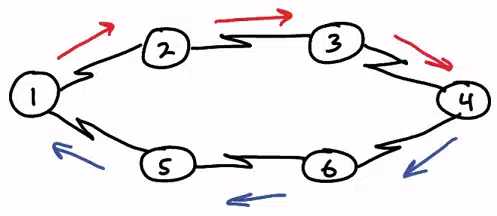
Może to spowodować problemy np. w sytuacji gdy na ścieżce przychodzącej (niebieska) znajduje się stateful firewall – ruch powrotny nie będzie mu znany ponieważ sesja została zarejestrowana na firewallu na ścieżce wychodzącej (czerwona). Cisco ASA mógłby sobie z tym problemem poradzić dzięki sparowaniu obu zapór w zsynchronizowany klaster, ale nie każdy firewall oferuje taką możliwość. Mogą również wystąpić problemy z NAT’owaniem oraz z opóźnieniem w transmisji gdy jedno z łącz jest bardziej wykorzystywane od drugiego. Ponadto routing asymetryczny może przyczyniać się do powstawania kolejnego problemu na naszej liście: unicast floodingu.
Unicast flooding
Przełączniki otrzymując ramkę z nieznanym adresem docelowym domyślnie wysyłają tę ramkę unicastem na wszystkich portach (poza nadawczym) w celu dotarcia do odbiorcy – nie jest to nic dziwnego gdyż jest to standardowe zachowanie switcha, gwarantujące dostarczenie pierwszej ramki w danej konwersacji. Problemem są jednak takie niekontrolowane zalewy ramkami unicastowymi, a problem ten zwie się „unicast flooding„.
Wyróżnia się trzy przyczyny powstawania takiego niekontrolowanego ruchu:

- Routing asymetryczny: jeśli przełącznik nie zna danego MAC’a to roześle unicast flooding, to już wiadomo. Jeśli ten przełącznik nie otrzyma ruchu powrotnego (a w przypadku routingu asymetrycznego tak się właśnie może stać) to będzie on wysyłał unicast flooding za każdym razem gdy będzie musiał wysłać pakiet do nieznanego adresu MAC. I tak w nieskończoność. Ponadto pakiety powrotne przechodzą ścieżką, w której adresy docelowe MAC również mogą być jeszcze nieznane przełącznikom po drodze. Pakiety te spowodują zatem również powstawanie unicast flooding na ścieżce powrotnej. Rozwiązaniem mogłoby być dodanie statycznych adresów MAC, aczkolwiek jest to mało skalowalne – lepiej skupić się na pozbyciu asymetrycznego przepływu danych.
- Zmiany w topologii STP: za każdym razem gdy następuje zmiana w topologii STP rozsyłane są komunikaty TCN – Topology Change Notifications, w celu poinformowania pozostałych przełączników o zmianie. Poza zalewaniem sieci TCN, problemem może być również związany z nimi mechanizm skracania aging time tablicy MAC (domyślnie z 3 minut do 15 sekund). W przypadku wygaśnięcia dużej ilości wpisów sieć jest narażona na zwiększoną ilość unicast flooding aby ponownie nauczyć się lokalizacji hostów. Szczególnie paskudne są „flapujące” hosty – to one powodują rozsyłanie nadmiarowych TCN. Rozwiązaniem tego problemu jest właściwe zaprojektowanie topologii STP oraz ograniczenie ilości rozsyłanych TCN poprzez uruchomienie PortFast na portach dostępowych.
- Przepełnienie tabeli MAC: to jest znany problem – w momencie, w którym tabela MAC ulega przepełnieniu, przełącznik działa jak hub – generuje unicast flooding. Najczęściej przyczyną przepełnienia jest atak hakerski, ale funkcja port-security dobrze sobie radzi z tym problemem.
Jako ciekawostkę można dodać, że o ile port-security zabezpiecza port przed nieznanymi żródłowymi adresami, to istnieje również funkcja zabezpieczająca port przed braniem udziału w samym procesie unicast floodingu. Funkcja ta to Unknown Unicast Flood Blocking (UUFB), a uruchamia się ją z poziomu interfejsu komendą switchport block unicast. Dobrym miejscem na zastosowanie tej funkcji mogą być np. wyizolowane porty private vlan.
Micro-bursts
Micro-bursts to nazwa, którą określamy krótkotrwałe skoki wykorzystania łącza do 100%. Spowodowane są one nagłymi wyrzutami dużych ilości pakietów do sieci, które w rezultacie mogą powodować przepełnienia buforów pamięci i zatłoczenie (congestion). Efekt jest krótko-trwały i wielokrotnie niedostrzegalny, jednakże powoduje mikro-opóźnienia w sieci, które mogą być istotne np. dla firm z branży finansowej.

Micro-bursts mogą spowodować:
- odrzucanie oraz opóźnianie ramek/pakietów
- zatłoczenie na łączach, które skupiają większe ilości ruchu (np. w warstwie dystrybucyjnej gdy intensywny ruch z wielu serwerów wpada w niewielką ilość łącz między warstwą core i dystrybucyjną a ich przepustowość jest za niska)
- niedotrzymywanie SLA
- błędy w działaniu aplikacji (zwłaszcza tych podatnych na niewielkie opóźnienia w transmisji)
Micro-bursts są ciężko dostrzegalne ponieważ wykresy wykorzystania łącza w interwale 1-minutowym pozostają niskie. Rozwiązaniem problemu jest przede wszystkim zastosowanie traffic-shapingu.
Out-of-order packets
Problemem dla niektórych aplikacji mogą być pakiety otrzymywane nie w kolejności. Problem ten dotyczy zwłaszcza UDP, który nie posiada wbudowanego mechanizmu składania segmentów (reassembly) z powodu braku numerów sekwencyjnych. Problem ten dotyczy również TCP gdy ilość pakietów poza kolejnością jest zbyt duża – powoduje to, że odbiorca buforuje pakiety (spowalniając przepływ danych do wyższych warstw i tym samym osłabiając ich wydajność) oraz wysyła duplicate ACK’s prosząc nadawcę o szybką retransmisję. W następstwie zwiększa się stopień wykorzystania sieci oraz CPU po obu stronach transmisji. Ponadto nadawca interpretuje tę sytuację jako powstanie zatłoczenia w sieci i ogranicza congestion window spowalniając cały ruch. Spowolniony ruch TCP przechodzi w fazę slow start i jeśli takie przerwania następują często to może on nie dać rady się „rozpędzić” ponownie.
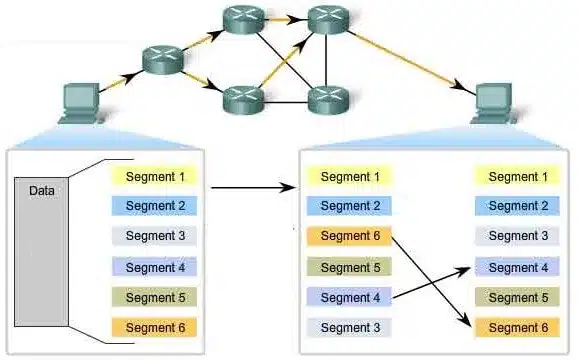
Powodami takiego stanu rzeczy mogą być:
- istnienie wielu ścieżek w sieci (zarówno w warstwie drugiej jak i trzeciej) i stosowanie load-balancingu per packet
- manipulacje na pakietach związane z QoS (przede wszystkim gdy pakiety przechodzą dwiema ścieżkami, z czego jedna z nich jest optymalizowana)
- problemy z routingiem powodujące tymczasową niedostępność niektórych tras
Rozwiązaniem problemu mogą być:
- wybieranie ścieżki przepływu danych per-destination (per-session) – czyli coś co oferuje CEF
- mechanizm składania segmentów wykorzystywany w TCP
- zezwolenie na procesowanie nieposkładanej mieszanki pakietów na urządzeniach pośredniczących takich jak IPS czy firewalle (urządzenia te mogą domyślnie odrzucać pakiety przychodzące w niewłaściwej kolejności)
Troubleshooting
Opisane powyżej problemy nie należą do często pojawiających się – warto jednak mieć świadomość ich istnienia. Nigdy nie wiadomo kiedy taka wiedza się przyda w troubleshootingu… 🙂 Przeczytasz o tym w naszym darmowym NSSletterze – mailingu dla sieciowców głodnych wiedzy.
Dołączając uzyskasz dostęp również do archiwum – tematykę tego artykułu rozszerzyliśmy w NSSletterze 042. Rozwiń swoją wiedzę już teraz i zapisz się używając formularza poniżej.

Wiele lat temu unicast flooding spowodowany przez ruch unicast udp PVR/VOD robił nam w sieci sporo problemów. Rozwiązaniem okazało się skorelowanie arp timeout w L3 z fdb-aging time w L2, tak, by arp timeout był minimalnie krótszy niż fdb-aging, dzięki czemu tablice fdb dla aktywnych urządzeń nie wygasały
Komentarz – ZŁOTO 💗 Dzięki!
Mam małą prośbę aby zamiast słowa utylizacja używać słowo np. wykorzystanie.
Hmm, w punkt! Faktycznie jest to niezbyt trafna kalka z j. angielskiego. Już teraz wiem, że ciężko mi osobiście będzie się przestawić, ale podejmę ten wysiłek 😉 Jeżeli się oduczyłem mówić \”autentykacja\” to i z \”utylizacją\” sobie poradzę 😀 Dzięki!